DeepSeek propose une nouvelle architecture pour optimiser l'entraînement des modèles de langage
DeepSeek vient de publier un rapport de recherche, co-signé par son fondateur Liang Wenfeng, proposant une révision de l’architecture fondamentale utilisée pour l’apprentissage profond.
Le document présente les « Manifold-Constrained Hyper-Connections » (mHC), une méthode qui stabilise l’entraînement des modèles d’intelligence artificielle tout en maîtrisant les coûts. Elle s’inscrit dans une stratégie visant à rendre les modèles plus économiques et rivaliser avec des concurrents américains mieux financés et disposant d’un accès supérieur à la puissance de calcul.
Une recherche de stabilité à grande échelle
Le mHC est une évolution des Hyper-Connections (HC) introduites par ByteDance en 2024 pour améliorer le standard ResNet établi depuis une décennie. Si les HC augmentent la largeur du flux résiduel pour améliorer la performance de ResNet, elles le font en sacrifiant la propriété de mappage d’identité.
Selon l’équipe de 19 chercheurs de DeepSeek, cette lacune provoque une instabilité sévère lors de l’entraînement où une amplification non bornée du signal peut aboutir à une explosion ou une disparition des gradients. L’élargissement du flux résiduel augmente aussi les coûts d’accès mémoire, limitant la scalabilité des modèles.
Des solutions algorithmiques et infrastructurelles
L’innovation de mHC consiste à projeter les matrices de connexion résiduelle sur le polytope de Birkhoff, l’ensemble des matrices doublement stochastiques. Cette projection géométrique « contraint » le réseau HC et restaure la stabilité du signal.
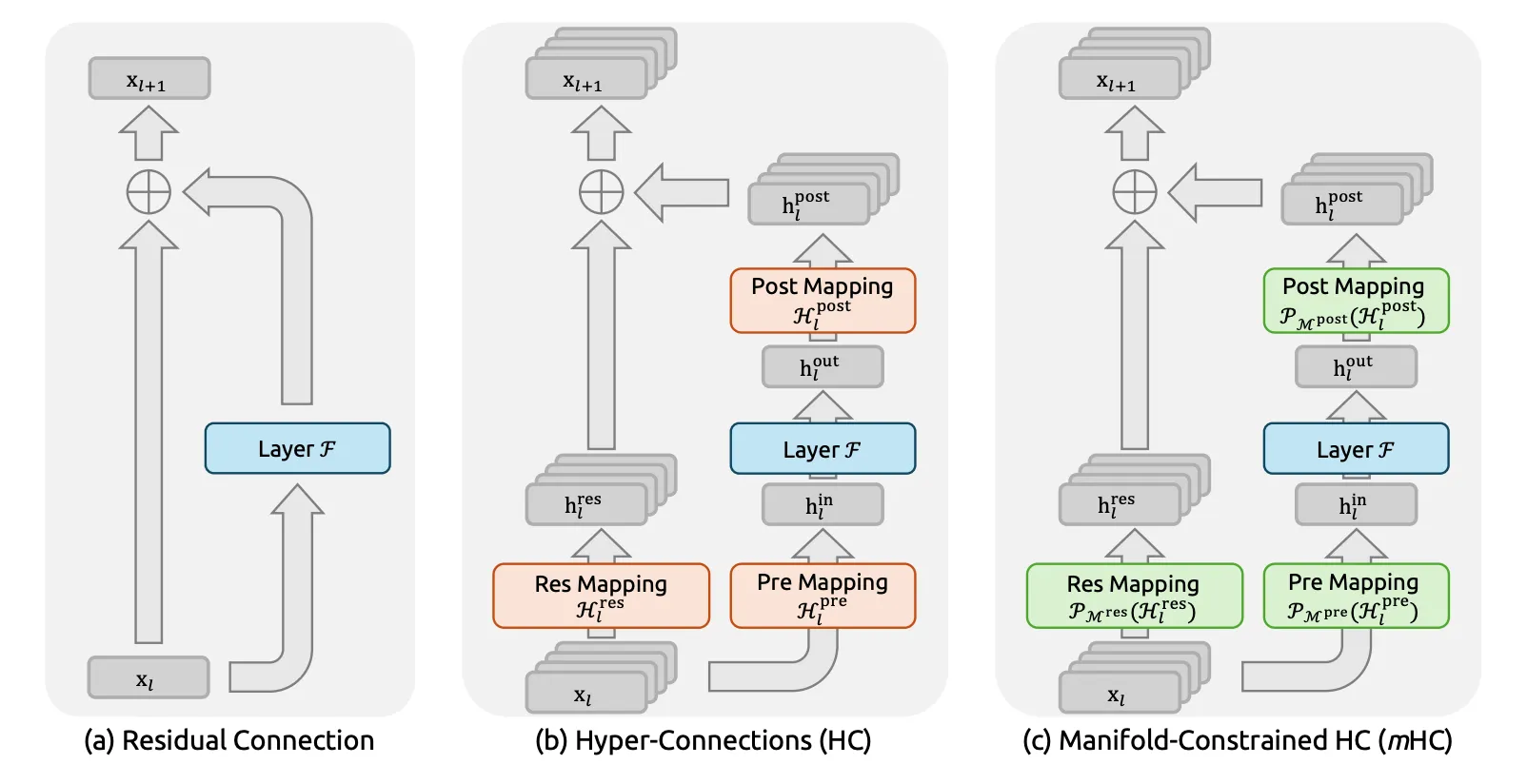
Au-delà de l’innovation algorithmique, des optimisations au niveau de l’infrastructure — fusion de noyaux, recalcul sélectif, chevauchement des communications et du calcul, etc. — atténuent l’empreinte mémoire de la méthode et en assure la viabilité pratique.
Testée sur des modèles de 3, 9 et 27 milliards de paramètres, l’architecture mHC a démontré une scalabilité supérieure à HC et des gains de performance constants.
Implications pour les modèles futurs
Pour les analystes, ce papier signale la direction technique des futurs modèles de l’entreprise. Selon Pierre-Carl Langlais, co-fondateur de la start-up française Pleias, la publication prouve la capacité de DeepSeek à réingénier chaque dimension de son environnement d’entraînement, une caractéristique des laboratoires de pointe.
Alors que la plupart des start-ups IA s’efforcent désormais d’exploiter les capacités des LLM pour sortir de nouveaux produits, DeepSeek continue de se focaliser sur l’amélioration des mécanismes fondamentaux de l’apprentissage machine. Il est à noter que le document a été déposé sur arXiv par Liang Wenfeng lui-même, un geste qui souligne l’importance accordée à cette recherche et la culture d’ouverture croissante des acteurs chinois de l’IA.